0402 腾讯光子工作室后台开发一面
简单打个广告,字节云基础存储团队内推直达,可私信咨询,内推码 GX424YN:
https://jobs.toutiao.com/h5/pdi/recruit/storageToB?ref=fuyongxing\&code=GX424YN
更新:已凉但是学到了很多,今年只有腾讯和字节的面试机会,腾讯的这个凉了之后后面也顺利拿到了字节基础架构的后端实习,五月份就入职啦,字节的面经在下一条讨论里面
之前有些个人回答是错误的,因此清空了个人回答,后续会慢慢更新问题答案,也作为个人的一个反思啦
时长差不多 80-90min。
原定 19:30 开始,面试官来晚了十几分钟
首先介绍流程:1 自我介绍 + 项目介绍 -> 2 技术问题 -> 3 问面试官问题
我:自我介绍,一段实习
面试官:实习时候遇到的问题,如何解决的
面试官:简单介绍下你的项目
面试官:好的,现在开始问技术问题。你会 C++ 吗
我:最近不常用,比较基础
问题:
1 udp tcp 区别
TCP 是面向连接的可靠传输协议,面向字节流,能够确保每一个字节都按序到达接收端,会发生粘包和拆包现象,有拥塞控制,适合对数据传输可靠性较高的场景。
UDP 是无连接,不可靠的,尽最大努力交付,面向报文,不拆分不合并,不会有粘包和拆包现象发生,无拥塞控制,适合可容忍部分数据丢失的实时应用,能够实现 1 对 1,1 对多和多对多的实时交互通信。
UDP 的首部长度只有 8B,相比 TCP 开销很小
2 tcp 如何保证可靠传输的
TCP 通过按字节序号,累计确认,超时重传及快速重传确保传输的可靠性
3 选择重传,超时重传与快速重传的详细过程
选择重传:
TCP 采用选择重传,滑动窗口,捎带确认,MSS (最大报文段大小),以及对接收窗口和发送窗口大小进行约束来确保传输效率
TCP 使用选择重传的方式来处理丢失的报文段,当 ACK 报文到达发送方,如果 ACK 序号在滑动窗口左边界以左则直接丢弃这个报文,如果该序号对应的报文在已发送待确认的序号之间,则确认该序号以前的数据被接收,并已该序号为开始选择报文段进行重传
如图,ACK = 5,则确认 4 到达,并以 5 为开始选取新的报文段重传 (由于涉及到将字节划分为报文段,实际中选择重传的过程可能更加复杂,但是叙述到这里足够了) 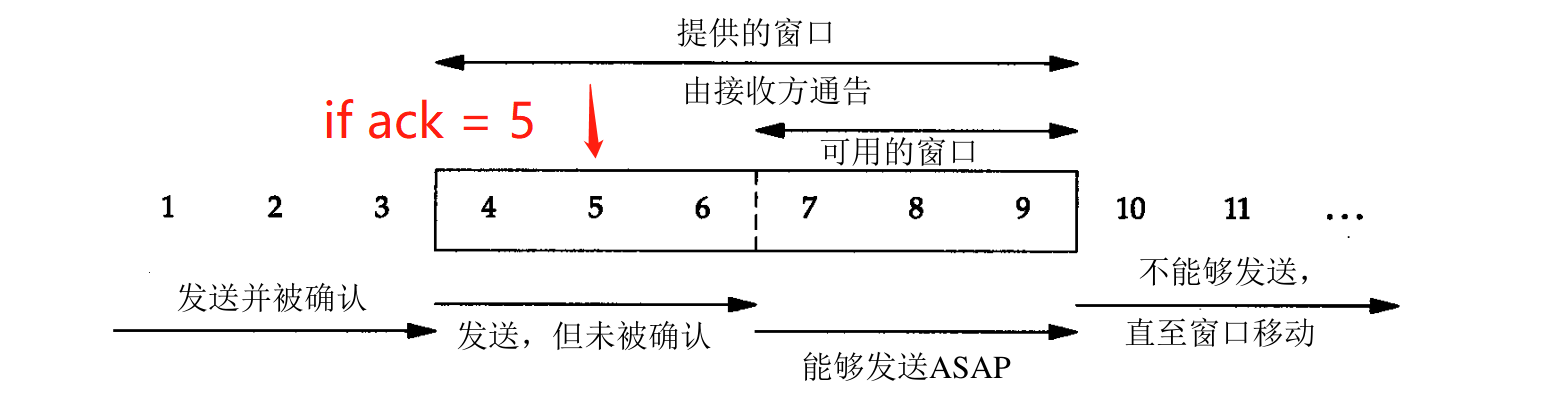
超时重传:
TCP 会为每个已发送的报文段维护一个计时器,当计时器超时时就会重传这一报文段,超时时间采用自适应算法实时更新。
当超时发生时就代表发生了阻塞,发送方会将 ssthresh 设为当前 cwnd 的一半,且将 cwnd 设为 1,结束拥塞避免过程,重新开始慢开始过程,即:ssthresh = cwnd/2, cwnd = 1
快速重传:
由于使用超时来控制重传存在超时周期太长的问题,在拥塞严重的情况下,由于会有大量的报文段丢失,这种方式会进一步增大发送时延,因此发送方往往还会采用冗余 ACK 的来控制重传,即拥塞控制中的快速重传过程,当连续收到 3 次对于同一序号的 ACK 时,触发快速重传,立即以该序号为开始选择一报文段重传,并且发送方将 cwnd 设为当前的一半,即:cwnd /= 2,然后快速恢复,即继续进行拥塞避免或者慢开始过程
4 发送者如何分辨接收方发来的 ack 是对乱序到达报文段的 ack 还是对重传后报文段的 ack
看个例子先理解下题吧:

乱序到达的情况:
如果第 2 个报文段,在传输过程中延时到达接收方,接收方先收到了第 1 个和第 3 个报文段,会向发送方发送序号为 1025 的 ack
超时的情况:
如果第 2 个报文段,在传输过程中超时了,接收方先收到了第 1 个和第 3 个报文段,会向发送方发送序号为 1025 的 ack
这两种情况本质的区别是,报文段可能延时未到达,也可能已超时,即发送方如何分辨报文段当前是延时未到达,还是已超时
这对于发送方来说是无法判断的,因为发送方不能确定延时未到达的报文段会不会超时。如果 ack 接收时报文段未超时,则报文段可能是延时未到达也可能是已超时,按照快速重传的逻辑来处理,如果 ack 接收时报文段已超时,则报文段超时需要超时重传
5 tcp 服务器如果向客户端发送 1MB 数据,是如何得知 1MB 发送完的
每个 socket 建立时均会分配输入缓冲区和输出缓冲区,write/send 方法会向输出缓冲区写入数据,写入方式分为阻塞和非阻塞两种,write/send 调用成功返回结果表示的是向输出缓冲区写入成功的字节数,并不代表接收端已接收到的数据。
而阻塞和非阻塞的区别是,如果写入的数据大于输出缓冲区可用大小,阻塞写入方式会阻塞直到全部数据写入成功然后返回总的数据字节数,非阻塞方式则直接按照缓冲区可用大小写入,然后返回写入的字节数
因此,可以通过 write/send 方法调用的返回值确定这 1MB 是否写入成功
read/recv 的阻塞模式则指的是如果输入缓冲区无数据则一直阻塞,有数据则读取返回,如果要读的数据大小大于缓冲区可读数据大小,则只会返回可读的字节数
6 如果叫你设计一个聊天应用层协议,需要考虑哪些重要问题
要设计一个应用层协议需要考虑:1)首先是基于哪些网络层,传输层和应用层协议来分工完成整个聊天应用的通信和传输;2)应用程序还需要传输一些信息来控制程序运行过程,因此还需要自行来定义应用层协议
大致设计如下:
-
1 TCP/Websocket 协议维护长连接
-
2 UDP 进行消息/文件的传输和接收
-
3 HTTP/HTTPS 完成用户登录,用户注销等应用功能
-
4 设计类似于 ICMP 的辅助控制协议,在客户端和服务端之间传输协议控制命令,如控制 UDP 传输的可靠性,发送心跳包等等
对于辅助控制协议的设计则需要考虑:1)协议头的设计;2)基于哪种协议来完成,IP or UDP or TCP?
由于控制协议的消息很短,且无需维护长连接,那么排除 TCP,而且我们要设计的是应用层协议,那么排除 IP,使用 UDP 协议
协议头的设计这里参考一下 QQ 的协议:OICQ,听过许嵩《灰色头像》的都知道这个吧
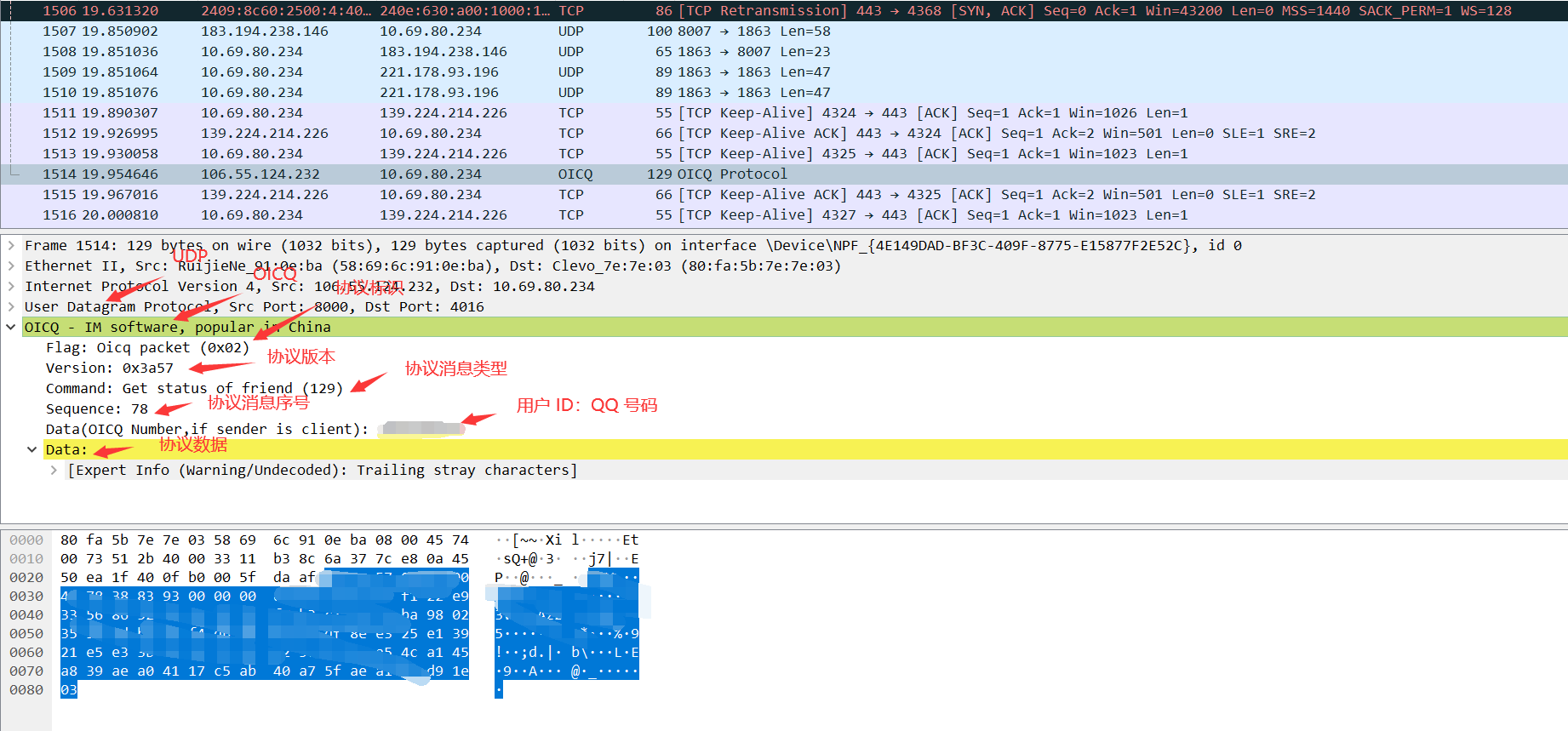
所以其实我当初的回答是基本正确的,面试官叫我还要考虑下协议数据包校验和,所以答案是:
-
Flag:协议标识
-
Version:协议版本
-
Command:协议消息类型,即协议控制命令
-
Sequence:协议消息序号
-
ID:用户ID
-
Data:协议数据
-
CheckData:校验和数据,可以放到 Data 中,感觉没啥必要
这里简单的看了一下这些数据包,发现 OICQ 的主要作用是传输一些控制命令和一些有助于协议运行的信息,而真正的聊天信息发送,文件传输,账户登录等等都还是基于 UDP/TCP 或 HTTP 来实现的
7 说一下共享内存
共享内存是一种用于线程间和进程间的通信方式,简单高效,但是存在并发问题
8 线程间共享内存和进程间共享内存的区别
同一个进程的线程共用同一个内存地址空间,共享静态变量,全局变量等,因此多线程可以直接通过全局变量来进行通信
多个进程则需要将一段共享内存映射到地址空间,通过向共享区读写来交换信息。
两者的区别是进程间共享内存需要额外考虑如何使得多个进程能够同时访问到这一块共享内存
9 如何实现共享内存
共享内存可以通过内存映射机制 memory map 和共享内存机制 shared memory 来实现,如 A-写者,B-读者 两进程通过共享内存通信:
参考:
1 内存映射机制 memory map:
○ A:建立映射 -> 写入文件
○ B:建立映射 -> 读取文件 -> 解除映射
2 共享内存/页表映射机制 shared memory:
○ A:key_t ftok(char* pathname, char proj); // 创建 IPC 通信 ID
○ A:int shmget(key_t key, size_t size, int shmflg); // 创建并打开共享内存,返回 shm_id,传入 key_t,共享内存大小 size_t,以及创建相关的 flag
○ A:void *shmat(int shm_id, const void *shm_addr, int shmflg); // 将内存挂载到当前地址空间,即进行页表映射
○ A:写入数据
○ B:int shmget(key_t key, size_t size, int shmflg); // 打开共享内存
○ B:void *shmat(int shm_id, const void *shm_addr, int shmflg); // 将内存挂载到当前地址空间,即进行页表映射
○ B:读取数据
○ B:int shmdt(const void *shmaddr); // 将共享内存从读取进程分离,即从页表中删除当前共享内存的页表映射
○ B:int shmctl(int shm_id, int cmd, struct shmid_ds *buf); // 操作共享内存,可用来写入/读取/删除共享内存,这里是删除共享内存,如果进程 B 提前宕掉,共享内存则得不到删除,会一直存在,只能通过 ipcrm 命令人工删除或重启内核
10 进程间其他的通信方式
信号,命名管道,匿名管道,信号量,共享内存和消息队列
这几种方式都非常重要,建议都像上述共享内存一样看一看代码实现的流程,如消息队列:
消息队列是保存在内核中一系列消息的链表,相比信号,消息队列能够传递更多的信息,相比管道,消息队列的消息有格式,类型和优先级,接受消息时可以选取特定类型的消息接收,消息队列的通信流程:
○ A:key_t ftok(char* pathname, char proj); // 创建 IPC 通信 ID
○ A:int msgget(key_t key,int flag); // 创建消息队列,返回 msgid,传入 key_t,读写相关的 flag
○ A:int msgsnd(int msqid,const void *prt,size_t size,int flag); // 发送消息
○ B:int msgrcv(int msgid,struct msgbuf *msgp,int size,long msgtype,int flag); // 接收消息
○ B:int msgctl ( int msgqid, int cmd, struct msqid_ds *buf ); // 管理消息队列,写入/读取/删除,这里是删除,同样如果进程 B 提前宕掉,消息队列则得不到删除,会一直存在,只能人工删除或内核重启
11 进程 A 创建了个共享内存,进程 B 来与它交流,如果两个进程同时宕掉了,这个共享内存会不会被回收
如果进程在调用 shmdt 函数前中止,系统会自动将进程与共享内存分离,这没有影响。但是如上所述,如果进程没有调用 shmctl 函数来删除共享内存,那么直到使用 ipcrm 命令人工删除或者重启内核,这一块共享内存均不会得到回收
12 一块共享内存,进程 A 作为生产者写了数据,如何告诉进程 B
共享内存的缺陷是缺乏同步与互斥机制,对于上述只有两个进程的情况,可以采取信号同步机制,也可直接在共享区设置特殊标记,进程根据标记判断是否有其他进程在读/写,多个进程的情况则需要使用信号量,包括互斥信号量和计数信号量
13 说一下 epoll
epoll 是 Linux 系统实现 I/O 复用的一种方式,epoll 只使用一个文件描述符来管理内核中注册的 I/O 事件表,不限制监听的文件描述符数量,且描述符数量不会影响 epoll 的性能,因为 epoll 是事件触发的,不是轮询,会为监听的一组事件注册回调函数,回调函数把就绪事件写入到应用进程传来的事件链表中。epoll 还使用 memory map 内存映射来加速与内核的信息交换,epoll 支持水平触发和边沿触发两种模式
这里附上一段本人整理的 I/O 模型八股文:
<--开始背
I/O 过程包括 I/O 事件处理和 I/O 数据读写两个阶段:事件处理阶段指当外围设备准备好数据后通过 DMA 技术将数据拷贝到内核缓冲区,或者将内核缓冲区的数据传送给外围设备;数据读写指数据在用户缓冲区和内核缓冲区之间的来回拷贝
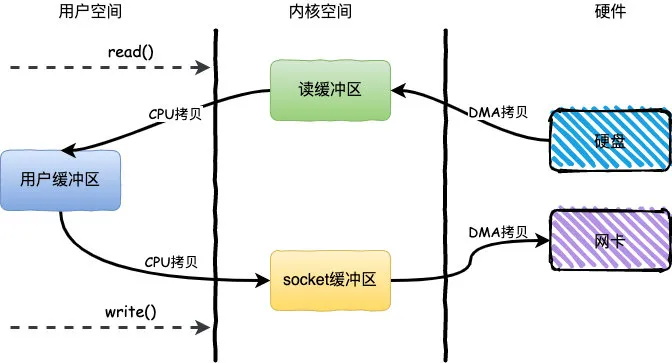
I/O 模型分为同步 I/O 和异步 I/O 。1)同步 I/O 指的是 I/O 事件处理与 I/O 读写过程相分离,I/O 事件由内核完成处理,I/O 数据在 I/O事件处理好之后由应用进程来完成读写。2)异步 I/O 指 I/O 事件处理和 I/O 数据读写均由内核来完成,进程请求数据后收到可读写信号后,可以直接读写
I/O 模型包括五种:阻塞,非阻塞,I/O 复用,信号驱动和异步 I/O,前四者都属于同步 I/O。I/O 复用,信号驱动,异步 I/O 是常用的 I/O 模型:
● Linux 中使用 select,poll,epoll 来实现 I/O 复用,其中 epoll 实现的 I/O 模型又可称为事件驱动 I/O,适合大用户场景
● Linux 中通过将 socket 缓冲区的文件描述符与宿主进程关联,当被关联的 socket 文件描述符可读或可写时会向宿主进程发送 SIGIO 信号来实现信号驱动 I/O
● Linux 中可通过 aio,io_uring 来实现异步 I/O,也可通过 epoll 来模拟异步 I/O,适合大数据量场景
I/O 复用select,poll 和 epoll
● select:
○ 轮询监听一组文件描述符的读写和异常事件,由于文件描述符 fd 参数是数组,最大数量限制是 1024,监听文件数量越多性能越差;
○ 文件描述符和监听的事件没有绑定,每次调用都需要分别传输,存在内存拷贝性能问题;
○ 返回整个事件集合,需要遍历才能知道哪些文件描述符上发生了事件;
○ 水平触发,工作线程可以不立即处理事件,select 下一次还会通知该文件的事件
● poll:
○ fd 参数是链表,无数量限制,同样是轮询,文件越多性能越差;
○ 文件描述符和事件绑定,但是每次调用都需要传输,存在内存拷贝性能问题;
○ 返回整个事件集合,需要遍历;
○ 水平触发
● epoll:
○ 只使用一个文件描述符管理在内核中的事件表,epoll 是事件触发的,不是轮询,在等待的一组描述符上注册回调函数,当事件就绪时,回调函数负责把发生的事件存储在就绪事件链表中,就绪事件链表是由用户传来的句柄;
○ epoll 只会返回已就绪的 I/O 事件;
○ 使用 memory map 加速与内核空间的信息传递;
○ epoll 支持 LT-水平触发-默认和 ET-边沿触发两种模式,边沿触发即工作线程需要立即处理事件,epoll 下一次不会返回该事件
还可以再继续看一下常用的事件处理模式:
参考:Linux 高性能服务器编程——游双
服务器需要处理三类事件:I/O 事件,信号与定时事件,常用的事件处理模式为 Reactor 模式和 Proactor 模式
Reactor 模式分为三个过程:事件注册,事件监听,事件处理,要求主线程 (I/O 处理单元)只负责监听文件描述符是否有事件就绪,有则立即将事件通知工作线程 (逻辑单元)处理
● 主线程向内核注册读就绪事件 -> 主线程 epoll_wait 监听读就绪
● 工作线程处理读事件 <- 主线程将读就绪事件写入请求队列<- 内核读就绪
● 工作线程向内核注册写就绪事件 -> 主线程 epoll_wait 监听写就绪
● 工作线程处理写事件 <- 主线程将写就绪事件写入请求队列<- 内核写就绪
Proactor 模式则将所有 I/O 操作都交给主线程和内核来做,工作线程可以直接对 socket 文件描述符进行读写,是一种异步 I/O,基于 aio_write, aio_read
● 主线程向内核注册读完成事件,告知用户读缓冲区位置,和读完成时的通知方式,如信号 -> 主线程继续处理其它逻辑
● 工作线程处理读事件 <- 每个信号会对应一个信号处理函数,选取一个工作线程 <- 内核读完成,socket 数据读入读缓冲区,信号通知主线程
● 工作线程向内核注册写完成事件,告知用户写缓冲区位置,和写完成时的通知方式,如信号 -> 工作线程结束,放入线程池
● 工作线程处理写事件 <- 每个信号会对应一个信号处理函数,选取一个工作线程 <- 内核写完成,用户缓冲区的数据写入 socket,信号通知主线程
epoll_wait 只能监听 socket 的连接请求事件,aio_write 和 aio_read 则能监听读写事件。但是 aio 的信号处理函数需要占用更多的内核空间,aio 适合大数据量,epoll 适合大用户。
也可以使用 epoll_wait 模拟 Proactor 即让主线程完成数据从内核 socket 文件描述符读入用户缓冲区,或数据从用户缓冲区写入 socket 缓冲区的过程
14 如何设计一个可以应对百万级请求的定时器。大概是这样,你需要实现 rpc 框架的一个功能,百万级的 rpc 请求到达,需要将请求传送给工作节点处理,维护一个定时器,定时器精度是 ms,期间部分 rpc 请求会得到响应,部分请求没有响应,则无响应的标记为超时,设计三个接口:
Add():添加一个请求
Del():响应一个请求并删除
Info():返回超时的请求有哪些
其实我的回答已经很像是时间轮了,但是没办法,没了解过,怎么答面试官肯定都不满意 Linux 内核中有两种高性能定时器的实现方式:时间轮和时间堆,详细的还没看。
15 redis 和 mysql 的区别
这个可以用我的回答就行,因为这俩东西的差别很大,面试官基本上提这个问题是问了引导出下一个问题,你擅长啥,这里就说啥,比如你擅长索引,这里就答索引不同,擅长事务就答事务不同好了
redis 是 NoSQL,非关系型数据库,工作在内存中,数据都是以 key-value 来存的。MySQL 是关系型数据库,两者在很多方面都不同,比如索引和事务
16 说说 MySQL 的索引
索引是存储引擎层的问题,要看存储引擎,常用的有 MyISAM 和 InnoDB。
两者索引结构都是 B+ 树,但 InnoDB 使用的存储方式是聚集索引,每个表有且仅有一个聚集索引。
聚集索引指不仅缓存索引还缓存真实数据。InnoDB 默认使用主键顺序 (可自定义索引)为行记录构建一颗 B+ 树,叶节点以页为单位,存放完整行记录,所有叶节点存放了整张表。
B+ 树 <-> 表,叶子节点 <-> 页
聚集索引的存储并不是物理上连续的,而是逻辑上连续的,叶子结点间按照主键顺序排序,通过双向链表连接。
非聚集索引也称为辅助索引,同样是一棵 B+ 树,通过非聚集索引查找主键,再通过主键 (作为索引)去主键索引内查找行记录。InnoDB 经过二次查找才可定位到行记录。
InnoDB 支持行级锁,事务,外键,热备份和容灾,事务隔离,MVCC 等,适合更新密集的场景
MyISAM 是顺序存储的,B+ 树叶节点存放的是行记录的物理地址,定位速度快,适合查询密集的场景
17 MySQL 为啥用 B+ 树
不用 hash 表是因为:
● hash 冲突
● 不支持排序和范围查询
不用 BST 是因为:
● 不可能一次性把索引全部装入到内存,只能逐一加载索引节点,因此 BST 的 I/O 次数过多,BST 是二叉树,树的高度更高,还存在极端情况的线性高度问题
● B+ 树单个节点包含的值越多,相对需要的 I/O 次数就越少
● B+ 树高度一般为 2-4 层,只需要 2-4 次 I/O
不用红黑树 (平衡二叉搜索树)是因为:
● 虽然红黑树结合了平衡树和 BST,解决了 BST 极端情况下的线性高度问题,但是依然存在着 BST 的缺点
● 红黑树,BST 更适合在内存中使用进行内部查找和排序
不用 B 树是因为:
● B 树的内节点也会存储 key 和 data,因此平均情况下,B 树的查找效率比 B+ 树更高
● 而 B 树的叶子节点是相互独立的,B+ 树叶子节点有指向相邻节点的指针,因此 B+ 树排序和范围查找的效率更高
● 因此 B 树更适合于做单一查询更多的数据库,如非关系型数据库,而 B+ 树则更适合做排序和范围查询更多的数据库,如关系型数据库
